


How to use NVIDIA Triton Server - The most powerful ML Model Serving Framework for Production
NVIDIA Triton Inference Server made simple. Learn how to deploy any Deep Learning model using Triton, in a hands-on - 10 min tutorial.

A warm welcome to the 37 new subscribers 🚀 who have joined NeuralBits!
Abstract
In this article, we’ll learn about NVIDIA’s Triton Inference Server, the most complex and widely used Model Serving Framework in production environments for both ML and Deep Learning models.
We’ll iterate on what Triton Server is, how it works, how to configure it, and all the features it includes.
We’ll also showcase a real hands-on example of taking a CNN (Convolutional Neural Network) model and deploying it using Triton Server while covering each step along the way using detailed explanations and code support.
Table of Contents
1. What is NVIDIA Triton Inference Server
2. Why using Triton for Production Deployments
3. How does it work?
4. Hands-on example using MobileNet v2 CNN
5. Implementing the Python Client
6. Insights from my daily work with Triton
7. ConclusionWhat is NVIDIA Triton Inference Server
NVIDIA’s Triton Inference Server [1] is an open-source software that provides a high-performance serving system for machine learning models. It’s designed to optimize and serve models for inference in production environments, ensuring efficient utilization of GPU and CPU resources.
Over 25,000+ companies worldwide use NVIDIA Inference AI as their serving environment for AI production workloads, ranging from use cases like recommender systems to large-scale deep learning vision systems and Generative AI.
Here are just a few:
Microsoft: integrates Triton into Microsoft Azure Cognitive Services to provide live transcriptions for Microsoft Teams calls using AI [2].
Samsung Medison: uses Triton to deploy AI models in medical imaging, enhancing diagnostic accuracy and speed.
Siemens Energy: implements Triton to enable highly complex power plants that are often equipped with cameras and sensors but with legacy software systems to join the AI revolution.
SnapChat: leverages Triton for real-time AI processing, cutting down serving costs by up to 50% and decreasing the serving latency by a 2x factor.

Why use Triton for Production Deployments
Triton started as a part of the NVIDIA Deep Learning SDK to help developers encapsulate their models on the NVIDIA software kit. It further branched out and was called TensorRT Server which focused on serving models optimized as TensorRT engines and further became NVIDIA Triton Inference Server — a powerful tool designed for deploying models in production environments.
In production environments, latency, workload distribution, and cost are critical factors for each AI product. Triton serves as a robust framework to handle and optimize for all these factors, including more.
Here’s why I recommend using Triton Inference Server :
If you want multiple frameworks — it supports TensorRT, TensorFlow GraphDef, TensorFlow SavedModel, ONNX, PyTorch TorchScript) and even vanilla Python scripts or C++ applications.
If you want to build pipelines — it supports ensembles of models to chain one or more models each possible using a different framework.
If you want performance observability out of the box — it automatically provides metrics on port 8002 in Prometheus data format which includes GPU utilization, server throughput, latency, and many more
If you want auto-scaling — seamlessly integrates with Kubernetes, and you can control gpu_clusters and model_replicas from within the model configuration files.
If you want API support — it includes Python, C++, and Java to name a few.
If you want different communication protocols: it exposes gRPC on port:8001 for high-frequency inference requests and HTTP on port:8000 for low/moderate request loads.
If you want to support A/B testing at ease — you can load multiple model versions under the same deployment on the same target format (TensorRT, ONNX, etc)
If you want classic ML algorithms support — besides deep learning optimized models, it offers support for XGBoost, LightGBM, and Scikit-Learn.
If you want to control the sync/async flow — it offers sync/async InferenceClients.
If you want to control memory at a lower level — it also offers shared-memory manipulation, both system-shared-memory and cuda-shared-memory.
Overall, if you’re in the position to decide or research efficient deployment frameworks for AI workloads, look no further than Triton Server. It has a steeper learning curve indeed, due to its multiple features and low-level control - but as a robust system, it offers high-level abstractions.
How does it work?
Setting up the Triton Server starts at the CUDA/GPU drivers level. Being designed for NVIDIA’s ecosystem, make sure that your system has CUDA, and NVIDIA Graphics Drivers installed such that the server can communicate with the underlying GPUs on your system.
A Triton Server instance can be both built from source using the C++ binaries or deployed as a container in your environment. The second option is the easiest one and the recommended one.
The core idea, in interfacing with the Triton Server is done in 2 steps.
Model Configurations:
Here, developers have to configure their models such that Triton can load and use them. As a developer, you’ll have to create a `model-repository` folder, where you’ll store all of your model configurations.
A model configuration is represented as such:model_repository └── prod_client1_encoder └── 1 └──resnet50.engine # eg. trained on 50 epochs └── 2 └──resnet50.engine # eg. trained on 100 epochs └── config.pbtxtWhere prod_client1_encoder is a folder that keeps 1..N model versions. In this case, we exemplify having 2 versions. The model versioning in Triton is INT-based, and you can add as many versions as you want.
Next, within these INT folder versions, we’ll keep the actual ML model, which can be in any ML framework format that Triton supports (e.g. PyTorch .pt, Tensorflow/Keras .h5, ONNX .onnx or TensorRT .engine).
In the end, for each model, there is a config.pbtxt file where we specify the configuration. Here’s how it looks:name: "prod_client1_encoder" # Name of the model platform: "tensorrt_plan" # Framework the model is in max_batch_size: 0 # Model handles 1 request/a time input [ # Defining input layer conf { name: "input_tensor" # Input tensor name data_type: TYPE_FP32 # Expected input datatype format: FORMAT_NHWC # Expected tensor format dims: [ 224, 224, 3 ] # Input tensor dims } ] output [ # Defining output layer conf { name: "output_tensor" # Output tensor name data_type: TYPE_FP32 # Output tensor datatype dims: [ 1000 ] # Output tensor dims } ] default_model_name="resnet50.engine" version_policy { # Specify versions we have specific { versions: [1, 2] } } default_model_version: 1 # Select default model versionThe Triton Client
Setting up the connection to the Triton Server via the Triton Client [3], which can be in Python, C++ or Java. Clients for each programming language can be built from source or installed (e.g. Python pip)
Here’s an example in Python:import tritonclient.http as httpclient # Model configuration model_input_name = "input_tensor" model_input_dtype = "FP32" model_output_name = "output_tensor" model_output_dtype = "FP32" model_name = "prod_client1_encoder" model_vers = "1" server_url = "localhost:8000" # Connect to Server client = httpclient.InferenceServerClient(url=server_url) # Prepare Input Tensor input_data = httpclient.InferInput( model_input_name, processed_image.shape, model_input_dtype) input_data.set_data_from_numpy(<raw_data_numpy>) # Send inference request request = client.infer( name=model_name, model_version=model_vers, inputs=[input_data] ) # Unpack output output = request.as_numpy(model_output_name)
Being based on a client-server model, the workflow goes like this:
Client packs the input data (image, text, audio).
Client specifies which model to use (by name and version)
Client sends the inference request to the server via either HTTP or gRPC.
Server receives a request and places it in a queue as Triton is designed to handle multiple requests simultaneously.
Server routes the request to the specified model from the model repository and runs inference.
Server sends the response back to the client using the same protocol gRPC or HTTP.
Client receives the response and extracts the result tensor() → numpy().
How does request-batching work
Request Gathering: multiple clients send requests for inference.
Dynamic Batching: the server accumulates incoming inference requests while it waits for a short time window (batching window) that is configurable in config.
Processing Batch: the server sends the batched requests to the model for inference.
Response to Clients: the server disassembles the responses and sends the individual results back to the respective clients.
Next, let’s go ahead and showcase the end-to-end workflow on a MobileNetv2 model, a popular deep-learning model for Image Classification.
Hands-on example using MobileNet v2 CNN
Before starting, make sure your system has an NVIDIA GPU, with CUDA, and NVIDIA Graphics Drivers installed.
Prerequisites
Let’s prepare the folder structure first.
# Create project directory mkdir triton_sample_project # Create model_repository directory mkdir triton_sample_project/model_repo # Create blueprint for a model in model-repository mkdir triton_sample_project/model_repo/mobilenet mkdir triton_sample_project/model_repo/mobilenet/1 touch triton_sample_project/model_repo/mobilenet/config.pbtxtDownload the MobileNetv2 Model
For this example, we’ll download and work with the model in .onnx format.wget -O mobilenetv2-12.onnx https://github.com/onnx/models/raw/main/validated/vision/classification/mobilenet/model/mobilenetv2-12.onnx?download= mv mobilenetv2-12.onnx triton_sample_project/model_repo/mobilenet/1/mobilenetv2.onnxGetting INPUT/OUTPUT layer metadata
First, we’ll have to inspect the INPUT/OUTPUT layer names and data types.
To do that, we can load and visualize our model using Netron, to get these details.
Head over to Netron Visualizer [4], load the .onnx model, and check the INPUT and OUTPUT layers for the NAME and DATA_TYPE.

Populating the config.pbtxt
Using the metadata from step 3, write the config file.# vim triton_sample_project/model_repo/mobilenet/config.pbtxt name: "mobile_net" platform: "onnxruntime_onnx" max_batch_size: 0 input [ { name: "input" data_type: TYPE_FP32 dims: [ 1, 3, 224, 224 ] } ] output [ { name: "output" data_type: TYPE_FP32 dims: [-1, 1000] } ] default_model_filename:"mobilenet.onnx"Save and exit, and let’s move on to configuring the .env file that will hold our Triton Container starting arguments.
Preparing the .env file
This file will hold arguments for when starting the Triton Servertouch triton_sample_project/.env # vim triton_sample_project/.env HTTP_P=8000:8000 GRPC_P=8001:8001 PROM_P=8002:8002 IMAGE=nvcr.io/nvidia/tritonserver:22.04-py3 MODEL_REPOSITORY=./model_repoDownloading and starting the Triton Server
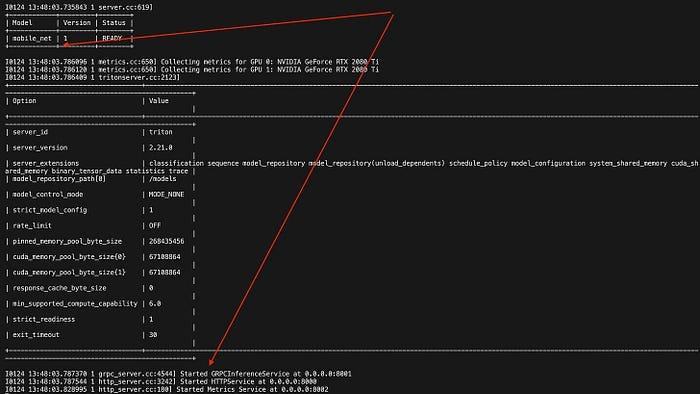
# Load env source triton_sample_project/.env # Start Server docker run --gpus 0 -d -p $HTTP_P -p $GRPC_P -p $PROM_P \ -v${MODEL_REPOSITORY}:/models \ --name sample-tis-22.04 $IMAGE tritonserver \ --model-repository=$MODELSInspect the Server Status
At this step, we’re making sure the server started OK and loaded the model without errors.docker logs sample-tis-22.04 --tail 40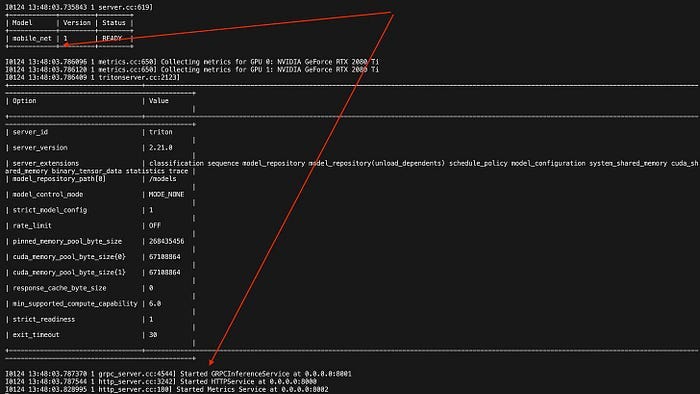
Downloading test data
For this example, we’ll download a dummy image and ImageNet labels file (since the MobileNetv2 model was trained on ImageNet, we need the labels to see if our model classifies correctly)# LABELS wget https://raw.githubusercontent.com/pytorch/hub/master/imagenet_classes.txt # IMAGE (of a pizza) curl https://www.healthyseasonalrecipes.com/wp-content/uploads/2019/12/greek-pizza-21-034.jpg > pizzaa.pngImplementing the Triton Client in Python
We’ll use the HTTP protocol to communicate with the Triton Server from our Python client. For that, we have to install these Python packages:pip install tritonclient, tritonclient[http]Implementing Image Preprocessing Steps
Since our model was trained on ImageNet, we need to preprocess our images such that they rely on the same data distribution as the ImageNet dataset. For that, we’ll need to:Resize the image to (224,224,3) - the shape our model was trained on
Center Crop - to keep the image’s context
Normalize MEAN/STD using ImageNet dataset values for the same color distribution.
import tritonclient.http as httpclient import numpy as np from PIL import Image from scipy.special import softmax def resize_image(image_path, min_length): image = Image.open(image_path) scale_ratio = min_length / min(image.size) new_size = tuple(int(round(dim * scale_ratio)) for dim in image.size) resized_image = image.resize(new_size, Image.BILINEAR) return np.array(resized_image) def crop_center(image_array, crop_width, crop_height): height, width, _ = image_array.shape start_x = (width - crop_width) // 2 start_y = (height - crop_height) // 2 return image_array[start_y : start_y + crop_height, start_x : start_x + crop_width] def normalize_image(image_array): image_array = image_array.transpose(2, 0, 1).astype("float32") mean_vec = np.array([0.485, 0.456, 0.406]) stddev_vec = np.array([0.229, 0.224, 0.225]) normalized_image = (image_array / 255 - mean_vec[:, None, None]) / stddev_vec[:, None, None] return normalized_image.reshape(1, 3, 224, 224) def preprocess(image_path): image = resize_image(image_path, 256) image = crop_center(image, 224, 224) image = normalize_image(image) return imageLoading and parsing the ImageNet classes file
with open("imagenet_classes.txt", "r") as f: categories = [s.strip() for s in f.readlines()]Defining Model Parameters
# == Server & Model Parameters == image_path = "./pizzaa.png" model_input_name = "input" model_input_dtype = "FP32" model_output_name = "output" model_output_dtype = "FP32" model_name = "mobile_net" model_vers = "1" server_url = "localhost:8000"Sending Inference Requests to the Server
# Preprocess the image processed_image = preprocess(image_path) # Define the Client connection client = httpclient.InferenceServerClient(url=server_url) # Define the input tensor placeholder input_data = httpclient.InferInput(model_input_name, processed_image.shape, "FP32") # Populate the tensor with data input_data.set_data_from_numpy(processed_image) # Send inference request request = client.infer(model_name, model_version=model_vers, inputs=[input_data])Unpacking and inspecting results
# Unpack the output layer as numpy output = request.as_numpy(model_output_name) output = np.squeeze(output) # Since it's image classification, apply softmax probabilities = softmax(output) # Get Top5 prediction labels top5_class_ids = np.argsort(probabilities)[-5:][::-1] # Pretty print the results print("\nInference outputs (TOP5):") print("=========================") for class_id in top5_class_ids: score = probabilities[class_id] for class_id in top5_class_ids: score = probabilities[class_id] print( f"CLASS: [{categories[class_id]:<10}]\t: SCORE [{score*100:.2f}%]" )The result:
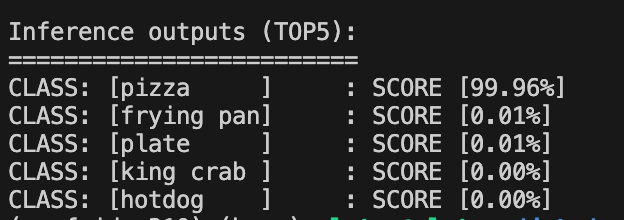
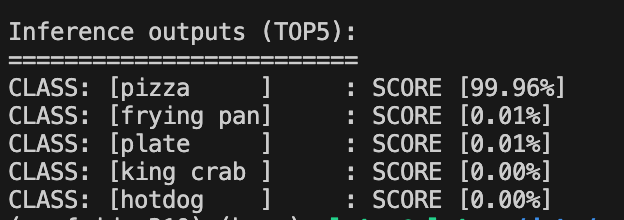
You can now order and enjoy a pizza, this tutorial has been quite long and detailed :)
⭐ Find all code resources for this article at NeuralBits Production Hub
Conclusion
Finally, let’s recap what we’ve learned today:
Triton Inference Server is an easy-to-set-up, scalable, and fail-safe solution to deploy and monitor your Deep Learning Models in production.
It offers multiple optimized backends (frameworks) where you can run your models, including ONNX, TensorRT, OpenVino, Tensorflow, and PyTorch.
It offers HTTP and GRPC protocols for low and high inference loads.
It handles request batching smartly and dynamically, ensuring that each client gets back a response.
The interface between client & server is straightforward, and model configuration is handled automatically by specified parameters in config.pbtxt
I’ve used it in multiple projects to handle several parallel RTSP cameras (25/30FPS) with ease.
It integrates with Prometheus and Grafana for Monitoring at a few click’s distance.
References
Link | Title | Year of Publishing
NeuralBits Production Hub, The Neural Bits GitHub, 2024
[1] NVIDIA’s Triton Inference Server, Triton Server Official Page, 2024
[2] Microsoft Teams calls using AI, Microsoft Teams AI Blog, 2021
[3] Triton Client, NVIDIA Triton Client Repository, 2024
[4] Netron Visualizer, Netron Visualizer for ML Model Architectures