


Deep Dive into NVIDIA NIMs for Generative AI
What is NVIDIA NIM™ ? What's the API structure? Expert insights from NIM™ team at NVIDIA.

Abstract
At the COMPUTEX 2024 conference, the CEO of NVIDIA, Jensen Huang announced new improvements in AI Robotics, GPU Architectures with the Blackwell chip, and plans for Digital Avatars.
One of the most interesting announcements, that relates to developers was the release of NVIDIA NIMs also known as NVIDIA Inference Microservices, that aim to simplify the process of deploying and iterating Generative AI into production.
After the announcement, a few blog posts on NVIDIA’s website described what these NIMs are, and how one could use them directly via the NVIDIA API catalog, where you can interact with them similar to the Hugging Face Spaces.
In the meanwhile, I was lucky enough to have the chance to chat with a few experts at NVIDIA, who work directly on NIMs and have gathered a ton of insights that I aim to share in this article.
Starting from what NIMS are, how they work, why NIMs are the most optimal solution for secure, scalable, and fast Generative AI solutions in production environments, and many more.
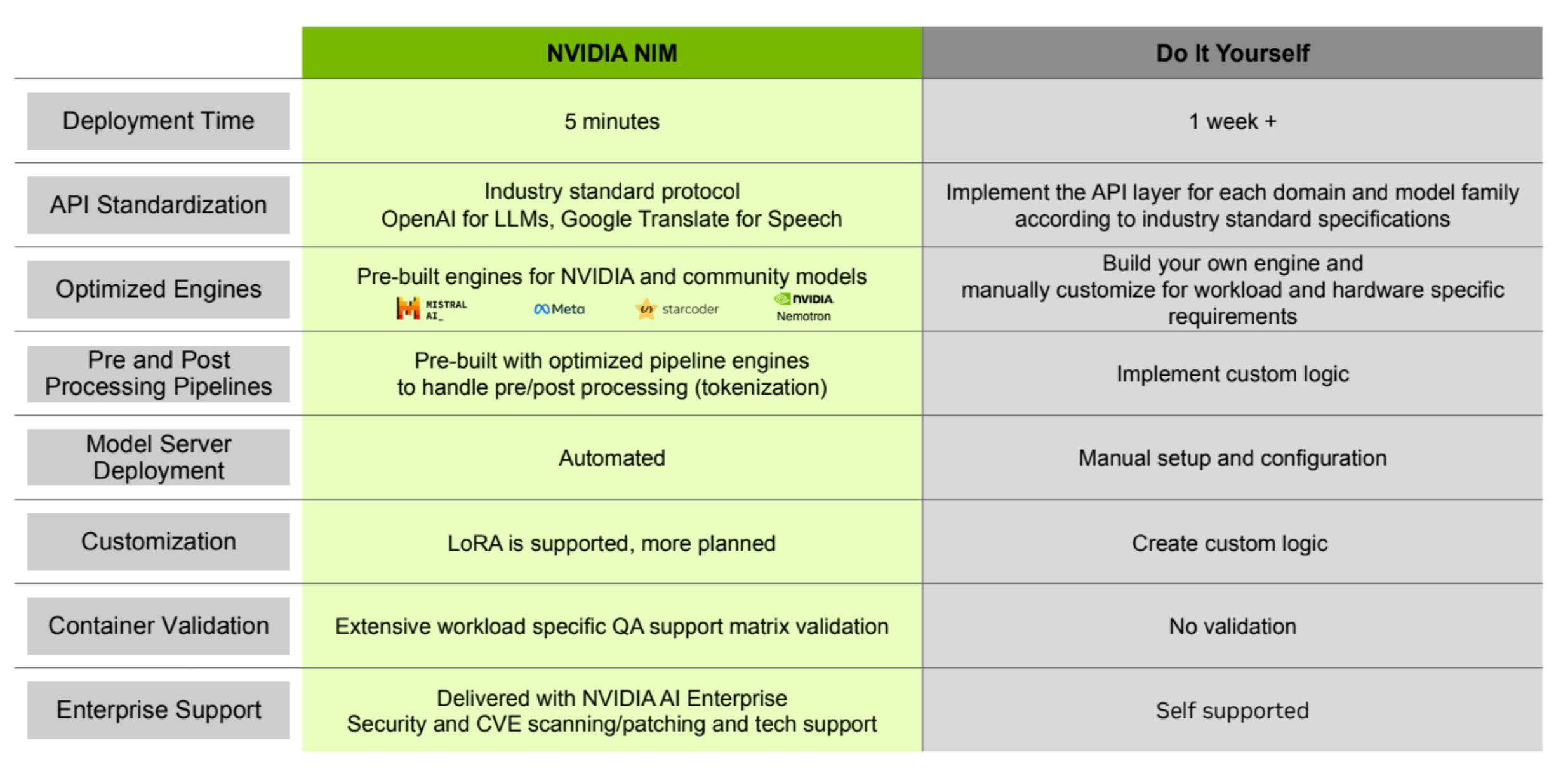
Table of Contents:
1. What is NVIDIA NIM
2. What’s inside a NIM service
3. Unpacking the NIM
4. Expert Insights
5. How to access NVIDIA NIMs
6. ConclusionWhat is NVIDIA NIM™
NVIDIA NIM™ is a set of easy-to-use microservices designed for secure, reliable deployment of high performance AI model inferencing across clouds, data centers and workstations.
It was specifically designed to encapsulate and deploy enterprise-ready Generative AI solutions into production environments. Using the latest optimization techniques, NIMs are fine-tuned for specific hardware architectures, providing optimal performance and efficiency.
We all agree that NVIDIA is currently the leading supplier of computing power necessary for AI development. From big tech to start-ups, all AI development and research is accelerated using NVIDIA GPUs and frameworks within NVIDIA’s software ecosystem.
NIMs, as easy-to-use microservices, streamline the deployment of generative AI models across the cloud, data centers, and workstations. They enable IT and DevOps teams to self-host large language models (LLMs) in their own managed environments while offering developers industry-standard APIs.
This allows the creation of powerful copilots, chatbots, AI assistants, and other GenAI-based solutions that can transform businesses.
Having NVIDIA’s cutting-edge GPU acceleration and scalable deployment at their core, NIM provides the fastest path to inference with unparalleled performance.

Further, let’s dive into what’s inside a NIM container, and see:
Components
Frameworks Used
API workflow
Model Lifecycle
What’s inside a NIM service
To cover this topic, let’s start with a tail-to-head approach, and talk at a high level about the frameworks that allow these fast inference times, and build up on tools and other NVIDIA frameworks that streamline that process.
NVIDIA CUDA
We know that to speed up any AI model, we need GPU acceleration. For that we would require NVIDIA CUDA, to benefit from the distributed execution of optimized kernels.
A kernel is a function that is meant to be executed in parallel on an attached GPU.
AI models are essentially complex chains of mathematical operations. In this context, kernels map the code to be executed to specific kernel functions, optimizing the execution of these operations on particular GPU hardware.
Now, to be able to map the code to GPU kernels we need a compiler that transforms the high-level AI model code into those kernels.
NVIDIA TensorRT Compiler
NVIDIA TensorRT is a compiler for deep learning models that is designed to maximize the performance of these models during inference. It achieves this by optimizing models via a complex workflow, reducing latency, increasing throughput, and more.
TensorRT Compiler is able to take any deep learning model architecture, which is effectively a graph of operations, and apply a complex chain of optimizations directly.
Some of these optimizations include:
Fusing Layers
Reducing the precision of layers (FP32 → FP16) to speed-up the computation time
Predefine GPU memory regions for tensor placeholders
Simplify Graph
Merge Operators
Compared to standard deep learning architectures like CNNs, transformer-based models add another layer of complexity due to their generative nature.
For example, for a CNN a forward pass through the network is straightforward. On the other hand, LLMs require KV caching, optimized FlashAttention or GEMM (general matrix multiply) for the Attention Head.
For the specific use-case of generative models, a specific extension of the TensorRT compiler was built, called TensorRT-LLM.
Having CUDA at the core that executes fast GPU kernels, and TensorRT-LLM that maps model graph operations to kernels, we lack a framework that completes this process allowing us to do that with high throughput and efficiency under multiple inference requests.
That brings us to the NVIDIA Triton Inference Server.
NVIDIA Triton Inference Server
The Triton Inference Server is designed to simplify the deployment of AI models at scale. Under the hood, it supports multiple Deep Learning frameworks to represent models (e.g. PyTorch, TorchScript, Tensorflow, TensorRT) and after loading these models into the GPU memory for fast execution, it provides a gRPC or HTTP wrapper interface to map inference requests to actual model execution.
The actual optimized inference request execution is only a part of the features, some others being:
Embedded monitoring via Prometheus - so you can accurately monitor the deployment at scale
Dynamic Batching - where it patches multiple concurrent requests together, does a single inference pass and returns responses to clients.
Extensibility - developers can customize any part of the workflow, build model pipelines, and more.
All these 3 pillars might become complex to manage independently, as with the intricacies of GPU architectures, GPU operations, and framework versioning - the difficulty increases.
That’s where NIMs come into play, as they already encapsulate all the required packages, frameworks, and optimizations such that the process of deploying AI workloads at scale is as easy as it can get.
Unpacking the NIM
NIMs are packaged as container images on a per model/model family basis. Each NIM is its own Docker container with a model. These containers include a runtime that runs on any NVIDIA GPU with sufficient GPU memory, but some model/GPU combinations are optimized.
Each NIM container is built from a common base, so once an NIM has been downloaded, downloading additional NIMs is extremely fast.
This allows developers to focus on the modeling part, and not care that much about optimizing and getting these models to run most optimally, since NIMs already package all the required tools and frameworks to solve that.
Next, let’s unpack what’s inside a NIM container 🔽
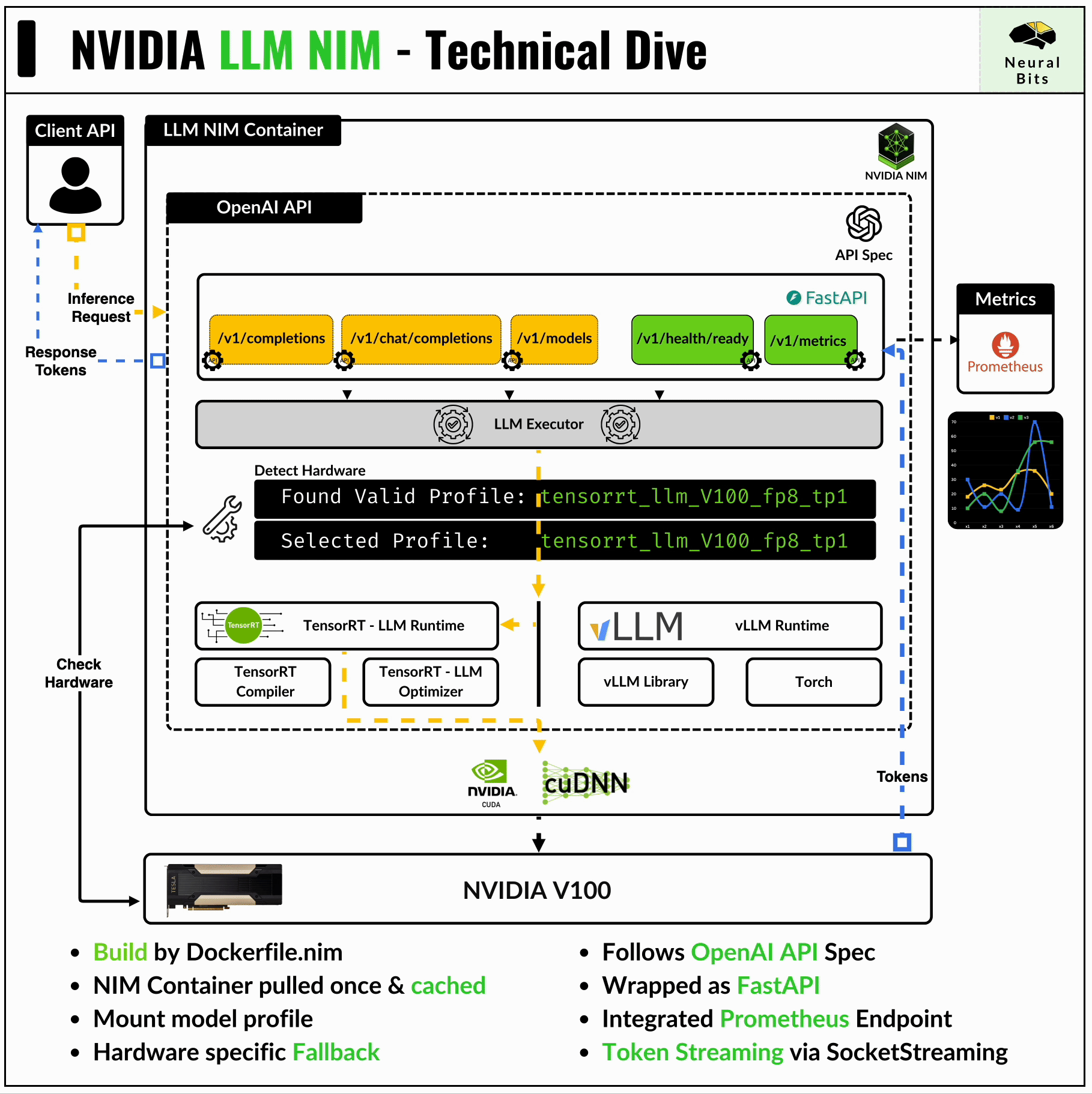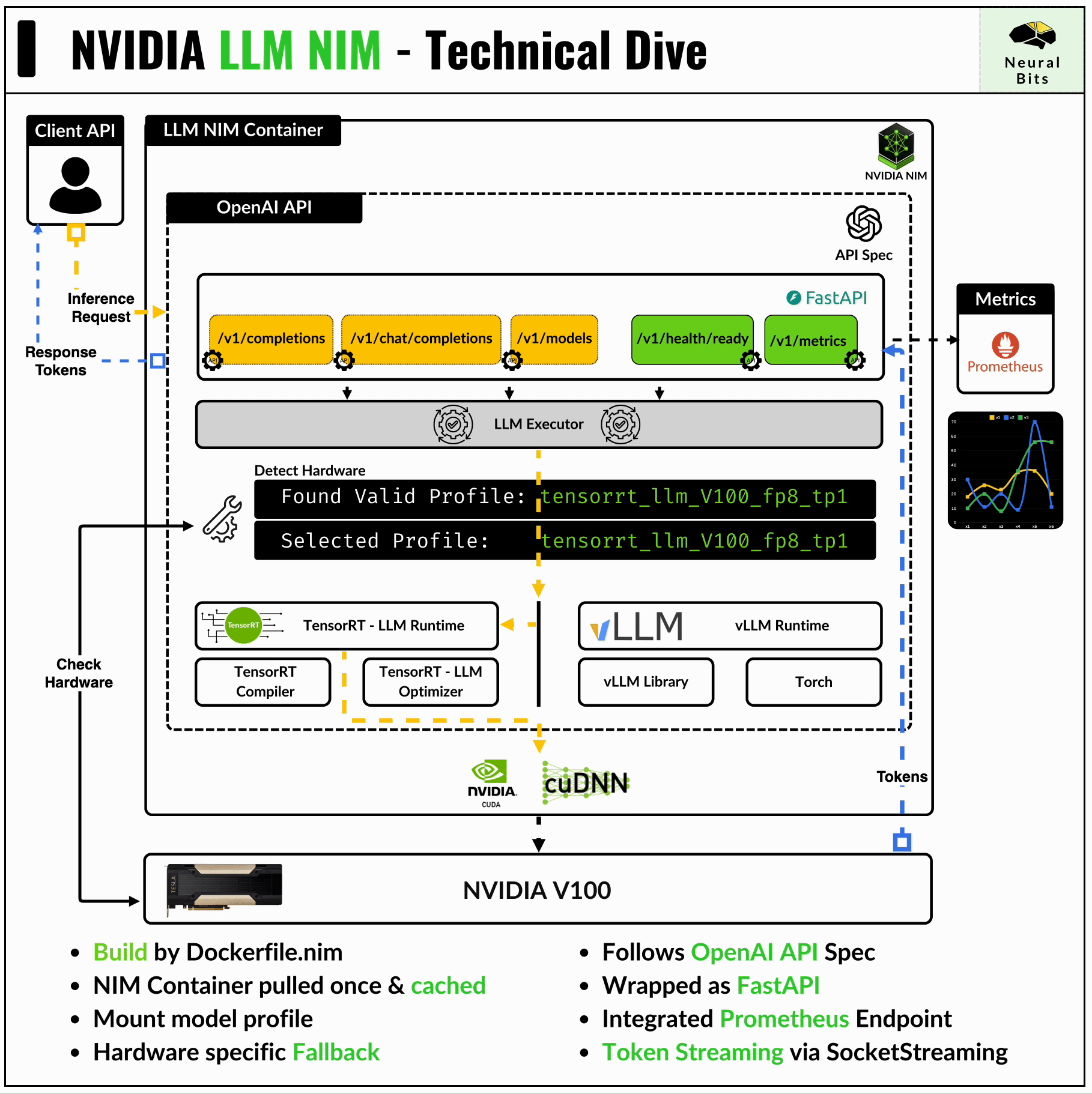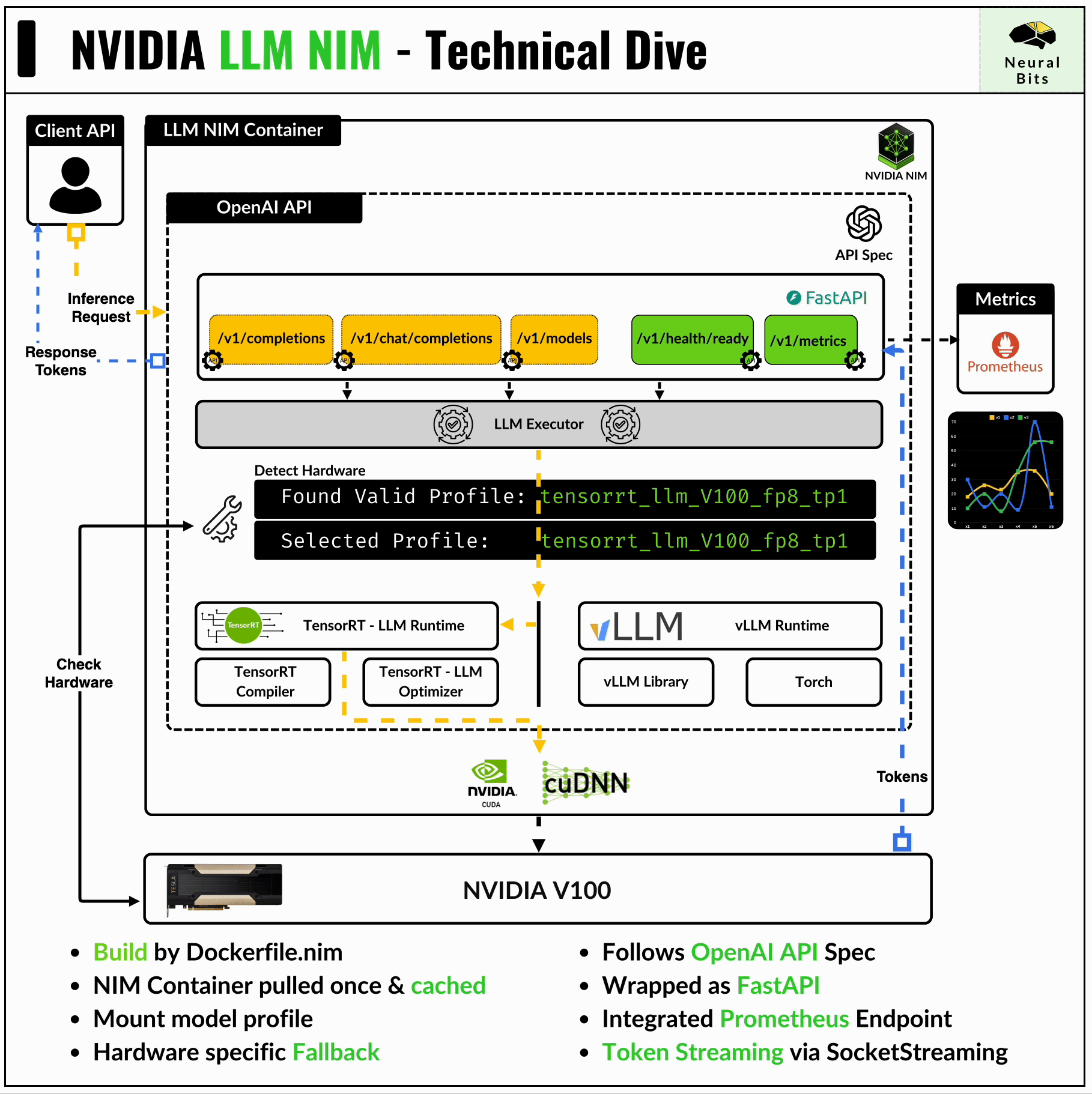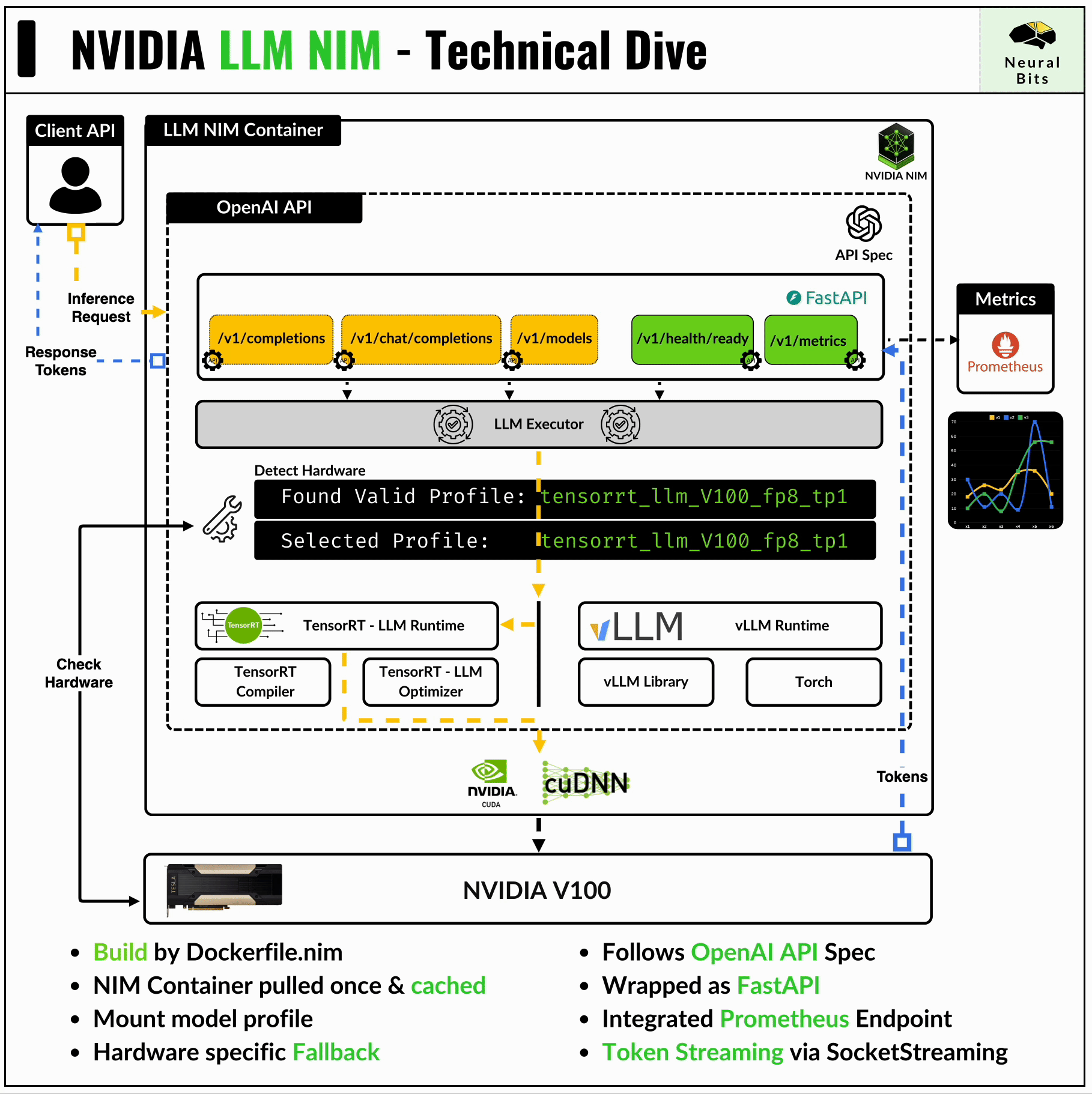
→ OpenAI API Specification
The NIM container has FastAPI underneath and exposes endpoints compatible with the OpenAI API.
from openai import OpenAI
client = OpenAI(
base_url = "https://integrate.api.nvidia.com/v1",
api_key = "$API_KEY_REQUIRED_IF_EXECUTING_OUTSIDE_NGC"
)
completion = client.chat.completions.create(
model="meta/llama-3.1-405b-instruct",
messages=[{"role":"user","content":"Write a limerick about the wonders of GPU computing."}],
temperature=0.2,
top_p=0.7,
max_tokens=1024,
stream=True
)
for chunk in completion:
if chunk.choices[0].delta.content is not None:
print(chunk.choices[0].delta.content, end="")These endpoints are:
/v1/completions - for one-to-one request response, without maintaining context after the prompt.
/v1/chat/completions - for chat, maintains context across requests.
/v1/models - to list available models within an NIM (this might include a base LLM model + multiple LoRA heads)
/v1/health/ready - to inspect container health
/v1/metrics - to stream extensive metrics via the Prometheus endpoint
→ Engine Profile Detector
Upon starting the NIM container, it automatically scans for the GPU on the system and looks up a compatible model profile optimized for that specific hardware.
GPU architecture and CUDA Capability are the factors by which the compatible model profile is selected.
The main profile is the TensorRT-LLM engine, but if this doesn’t exist on NGC, the container falls-back to downloading the vLLM profile for that model from HuggingFace.
→ LLM Executor
The LLM Executor is the gateway that interfaces with the FastAPI client API and the TensorRT-LLM & Triton Inference Server underneath.
It maps user requests to the execution environment and synchronizes the outputs which then are returned to the client that made the request.
→ Monitoring Endpoint
The NIM container streams multiple metrics via Prometheus, which can be captured in Grafana. These metrics include GPU, latencies, throughput, specific model stage metrics (e.g. tokenization time, post-processing times, etc), and overall container telemetry.
Expert Insights
In this section, let’s iterate on a few expert insights I’ve got from talking with some of the people working on NIMs at NVIDIA.
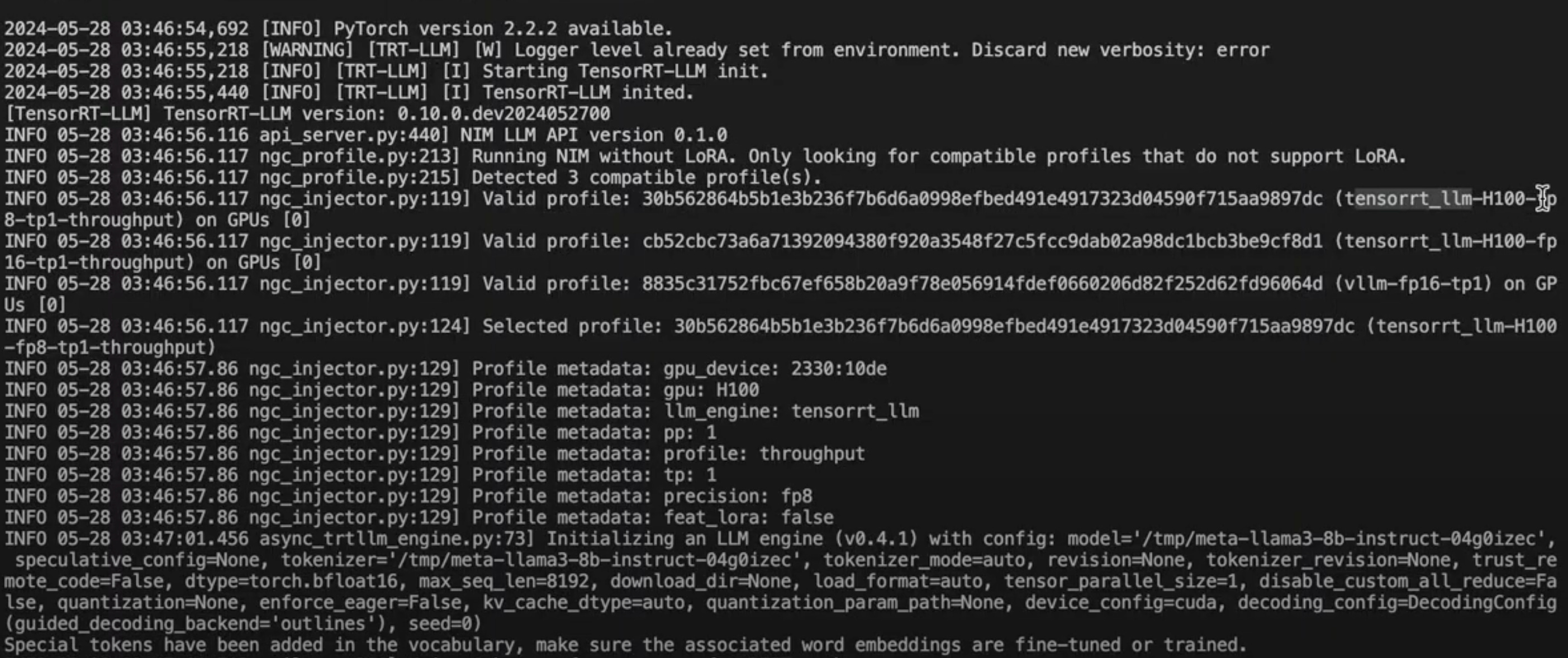
NIM Model Fallback
Once the NIM container is started, it profiles the GPU and then searches the NGC Catalog for the optimized model profile for that specific GPU.
If the TensorRT optimized engine for the specific model, doesn’t exist on NGC - the NIM setup falls back to vLLM and downloads the vLLM profile from the HuggingFace.
See this benchmark on vLLM and TensorRT-LLM (102 t/s vs 205 t/s)
Below, you can see this process in action 🔽

→ TensorRT Compatibility
An LLM model optimized with the TensorRT-LLM compiler is highly tuned to specific GPU architectures, identified by their CUDA computing capability.
CUDA Compute Capability is a metric used by NVIDIA to categorize and distinguish different generations and features of their GPU architectures. It consists of a version number that indicates the features and capabilities of the GPU.
Suppose you optimize a model for a GPU with a CUDA Compute Capability of 8.9 (like the NVIDIA H100 or similar). In that case, it is generally expected to work on all GPUs with the same Compute Capability.
For example, the consumer GPU RTX 4080 and the enterprise GPU L40 both have a Compute Capability of 8.9 and are based on the Ada Lovelace chip architecture.
A model optimized using TensorRT-LLM for the RTX 4080 can run on the L40. However, one important detail to remember is the performance difference, as the number of tensor cores and CUDA cores differ between these two GPUs.

→ Model Extensibility
One additional insight from the team working on NIMs is the LoRA (Low-Rank Adaptation) head inter-operability. This means that a single NIM can contain a base model (e.g., Llama 3.1 70B) and have a series of LoRA heads as version models that can be interchanged at runtime.
|--> llama3.1-70b-base
|____ lora_head_1
|____ lora_head_2How to access NVIDIA NIMs
One can currently get access to managed NIMs for free HERE, which is a similar interface to Hugging Face AI spaces.
For self-hosted NIMs, one must create an account on NVIDIA NGC Account and generate an API key to access NVIDIA’s container registry, where these NIMs are hosted.
Further, the deployment is straightforward:
export NGC_API_KEY = <generated_api_key>
export CONTAINER_NAME = meta-llama3-8b
docker run -it --rm --name=$CONTAINER_NAME \
--gpus all \
-e NGC_API_KEY \
-v $(pwd)/nim-cache/:/opt/nim/.cache \
-p 8000:8000 \
nvcr.io/nvidia/nim-llm-dev/meta-llama3-8b:24.05Below, you can see the run logs on a Hopper H100 🔽
Once the container has started, one can interact with it via the API client using:
from openai import OpenAI
client = OpenAI(
base_url = "http://0.0.0.0:8000/v1",
api_key = "not-used"
)
messages = [
{"role": "user", "content": Hi, how are you?"}
]
chat_response = client.chat.completion.create(
model="meta-llama3-8b",
messages=messages,
max_tokens=1024,
stream=True
)
for chunk in chat_response:
if chunk.choices[0].delta.content is not None:
print(chunk.choices[0].delta.content, end="")Conclusion
In this article, we’ve explored everything you need to know about the new NVIDIA Inference Microservices for GenerativeAI at an enterprise production scale.
Stay tuned, see you next week!
Leave a like or comment and don’t forget to subscribe! ;)